


从单体到分布式:支付架构演进的实战经验与最佳实践分析说明
支付系统作为金融科技领域的核心基础设施,其架构设计直接决定了业务的稳定性、扩展性和安全边界。从传统的单体架构向分布式架构的迁移,不仅是技术栈的替换,更是一场涉及业务逻辑、数据一致性、系统容错性以及运维复杂度的深刻重构。本文旨在从内部视角,详细剖析这一演进过程中的实战经验、关键决策点以及被反复验证的最佳实践。
必须承认单体架构在支付业务初期的价值。在用户量小、业务逻辑简单的阶段,单体架构的“应用、数据库、缓存、消息队列”一体化部署模式,具有开发效率高、部署简单、运维成本低的显著优势。随着支付场景的爆发式增长,例如用户突破千万、每秒交易吞吐量(TPS)超过千级、支持银行卡、余额、积分、第三方渠道等多种支付方式时,单体架构的致命缺陷开始暴露:高度耦合导致任何一项功能的修改都可能引发全系统停摆;数据库连接池与服务器资源的有限性成为性能瓶颈;代码臃肿使得每次上线都如履薄冰。
从单体迈向分布式的第一步,通常是进行“垂直拆分”与“水平拆分”。垂直拆分,即按业务域将庞大单体拆解为独立的服务,例如拆分为“支付核心服务”、“订单服务”、“账务服务”、“对账服务”、“风控服务”、“路由服务”等。这一阶段的实战经验表明:拆分粒度不宜过细,否则会导致服务间调用链过长,引发“分布式事务”难题;同时,每个服务必须拥有独立的数据库,彻底消除底层表级锁争用。水平拆分则聚焦于数据层面,典型做法是根据支付流水号或用户ID进行分库分表,例如将用户账户表按ID哈希分布到64或者128个物理库中,这解决了海量数据下的写入性能瓶颈。
在分布式演进过程中,最棘手的挑战莫过于“分布式事务”与“最终一致性”的平衡。支付系统要求极强的数据一致性,尤其在扣款、加款、创建订单等跨服务操作中,传统单体的本地事务机制失效。实战经验验证,直接采用两阶段提交(2PC)或三阶段提交(3PC)在互联网高并发场景下将导致严重的性能下降和锁定风险。因此,业界公认的最佳实践是引入“可靠消息事务”与“TCC(Try-Confirm-Cancel)模式”。例如,在用户发起支付时,支付核心服务先在本库中执行Try操作,预留资源,然后通过异步消息通知账务服务执行Confirm操作。如果中间发生失败,则通过补偿调度任务发起Cancel或回滚。系统必须引入“事务日志表”与“定时扫描补偿”的兜底策略,确保任何分布式操作最终达到“BASE(基本可用、软状态、最终一致性)”意义上的成功。
另一个不容忽视的实战经验涉及“服务治理”与“容错设计”。在分布式架构中,服务之间的调用依赖网络,网络抖动、超时、资源耗尽等异常变得常态。因此,必须全面实施“熔断、降级、限流、隔离”四大策略。例如,当风控服务响应变慢时,支付核心服务应主动熔断对该服务的调用,并返回系统默认风控通过(低风险阈值下)或直接拒绝交易,避免链路雪崩。限流方面,采用令牌桶算法或漏桶算法对网关层进行限流,保护后端核心数据库不被瞬间流量击穿。同时,为了防止分布式配置不同步导致的“幽灵bug”,必须引入集中配置中心(如ZooKeeper或etcd),实时推送配置变更。
数据一致性与高可用性的结合,还体现在“支付幂等性设计”上。支付过程中,因网络重试或消息重复投递,同一个支付请求可能被多次执行。最佳实践是:支付核心服务在接收到请求时,首先查询本地数据库中的“支付流水表”,检查是否已存在具有相同ID的记录。如果存在且状态为成功,则直接返回成功结果,不再重复扣款或状态更新。同时,为了防止重复支付导致的用户资金损失,资金账户的操作必须基于“唯一锁”(例如redis的分布式锁或数据库行级乐观锁),确保同一笔支付的扣款操作是原子性的。
在技术栈选型上,实战中验证的成熟方案通常包含以下组件:消息中间件选择Apache Kafka或RabbitMQ,主要用于解耦核心业务与异步任务(如对账、通知);数据库采用MySQL集群搭配分布式事务框架Seata或Sharding-JDBC;缓存层使用Redis集群应对高并发读取(如风控规则、渠道状态)。特别值得注意的是,数据库读写分离必须谨慎实施,因为支付交易以写入为主,主库承载大多数请求,从库用于后台报表和微弱查询,但切勿将核心交易路由到从库,以免读到脏数据。
运维与监控是分布式支付架构的隐形支柱。分布式系统中,一次支付失败可能涉及多个服务、多台机器、多条链路。最佳实践要求建立“全链路追踪”机制(如集成Zipkin或SkyWalking),每个请求携带唯一TraceId,贯穿网关、路由、核心、账务等所有节点。同时,监控指标必须覆盖:服务接口的TP99延时、数据库慢查询比率、消息队列积压量、支付成功率、渠道响应的超时次数等。一个常见且必须避免的陷阱是:过度依赖自动化测试而忽视灰度发布。对于支付系统,每次发布前必须在线上真实流量的极小比例(例如1%)进行灰度验证,观察错误率和响应时间,确认无异常后再全量上线。
从单体到分布式的支付架构演进,其本质是为了解决单点性能、数据一致性、系统可靠性以及业务可持续扩展性这四大核心矛盾。实战经验反复证明:拆分要适度、事务要补偿、治理要严格、幂等要彻底、监控要全景。没有一套架构可以永恒不变,但遵循上述最佳实践设计的分布式支付系统,能够在高并发、高可用、高安全的三角约束中找到平衡点,构成支撑亿级交易规模的金融基石。这不仅是对技术的考验,更是对系统设计哲学的一种沉淀。
从On-Premise本地到On-Cloud云上运维的演进
从On-Premise本地到On-Cloud云上运维的演进
从On-Premise本地化运维到On-Cloud云上运维的演进,是随着IT技术的不断发展和企业业务需求的不断变化而逐步实现的。
这一演进过程不仅涉及技术层面的变革,还深刻影响了企业的运维管理体系和业务发展战略。
On-Premise本地运维
在互联网服务和云计算兴起之前,企业的IT能力多建设在On-Premise本地部署基础之上。
企业基于其公司战略、运营模式、流程体系、组织架构等业务发展需要和特点,设计对应的IT架构,并通过建设自有数据中心或租用第三方IDC来构建IT基础设施资源。
在此基础上,企业搭建应用系统,以支持企业的发展。
随着互联网的发展,企业开始通过互联网与其客户紧密连接。
支撑企业对外服务客户的IT设计也逐渐发展和成熟,通过广泛应用开源软件,建立企业对客户的电子商务、社交网络、数据分析等能力。
这些开源软件解决方案的技术架构决定了对应的基础架构多以开源数据库、X86通用服务器、本地块存储、对象存储、数据以太网络为主。
这类基础架构组件以分布式部署、集群架构、横向扩展为显著特点。
因此,逐渐形成了以DevOps为最佳实践的运维管理体系,注重效率敏捷和快速响应业务需求。
在On-Premise本地运维阶段,企业会设立基础运维和应用运维团队,并格外重视硬件投资和基础运维工作。
由于基础设施资源有限,设备采购、部署实施和调整周期较长,运维团队会设立一系列制度和流程,管理和控制资源的使用以及容量规划。
On-Cloud云上运维
云计算的兴起,为企业建立有竞争优势的IT能力提供了更强的支撑。
企业IT组织利用云计算提供的按需自助服务、资源池化、弹性扩展伸缩、广泛网络连接等服务特性,进一步提升企业信息化和数字化能力。
在互联网企业中,由于天生就需要面对大流量高并发的业务需求,往往从第一天搭建开始就已经采用了Cloud Native或Cloud Friendly的系统架构和运维方式。
随着公有云服务的发展和成熟,互联网服务普遍采用All on 公有云或混合云的部署结构,这些企业会更适应On-Cloud云上运维形态。
运维的重心保持在如何支撑快速发展变化的业务规模、弹性响应业务波动、快速高效地管理大规模海量资源等方面。
演进趋势与总结
从On-Premise本地运维到On-Cloud云上运维的演进,是技术发展和业务需求共同推动的结果。
云上运维向更自动、更敏捷、更弹性的趋势演进,但本质始终是赋能业务永续运行,助力企业业务发展和战略目标的实现。
综上所述,从On-Premise本地运维到On-Cloud云上运维的演进是一个复杂而深刻的过程。
企业需要不断适应技术发展和业务需求的变化,加强运维管理体系的建设和优化,以确保业务的连续性和稳定性。
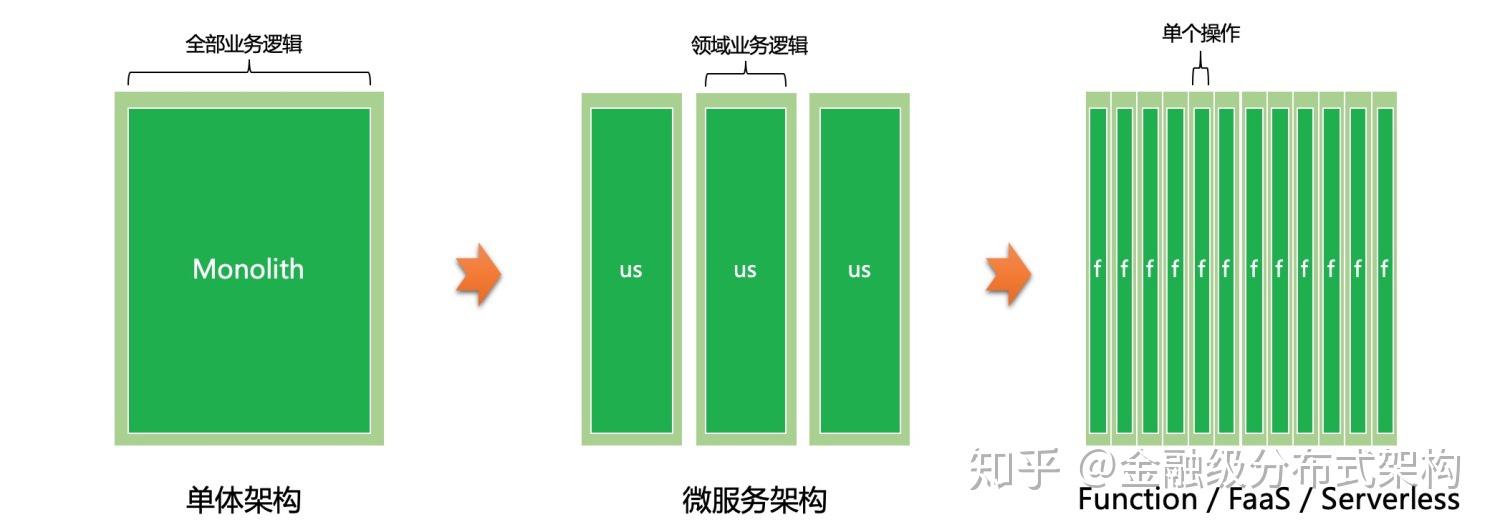
从零入门 Serverless | 架构的演进
从零入门 Serverless,架构演进过程可分为传统单体应用架构、微服务架构、云原生架构三个阶段,最终导向对 Serverless 的朴素理解——由平台系统管理机器而非人工运维。 以下为详细分析:
传统单体应用架构
微服务架构
云原生架构
架构演进与 Serverless 的关系
在架构的演进过程中,研发运维人员逐渐将关注点从机器上移走,希望更多地由平台系统管理机器,而非由人去管理,这就是对 Serverless 的朴素理解。













暂无评论内容