


在信息技术高速迭代的当下,应付系统作为企业财务流转与资金管理的核心枢纽,其数据处理能力直接关系到企业的运营效率与决策质量。随着业务规模的急剧扩张,特别是海量交易数据的涌入,传统的单一数据库架构逐渐暴露出性能瓶颈与扩展性不足的问题。为了应对这一挑战,支付数据库的分库分表策略应运而生,成为重构应付系统海量数据的关键技术路径。本文将从实践与挑战双重视角,详细分析这一复杂工程的实现过程与潜在难题。
分库分表的核心理念在于“分”,即通过将一张庞大的数据库表按照特定规则拆分成多个更小、更易管理的子集。在应付系统场景下,数据库通常承载着支付流水、供应商信息、应付账款、结算凭证等关键数据。传统模式下,所有数据汇集中于一张或有限几张表,随着时间推移,数据量可达数亿行甚至更多,导致查询响应缓慢、索引维护成本高、锁竞争严重,甚至影响整个支付流程的实时性。分库分表策略由此引入,它首先从逻辑上划分数据域。常见策略包括水平拆分与垂直拆分。垂直拆分更侧重于按业务模块分离,例如将供应商信息表与支付记录表存储于不同数据库实例;而水平拆分则专注于同一表内的数据分割,如按时间范围、供应商ID取模或地域分类将数据分散到多个数据库或表中。
从实现角度而言,应付系统的分库分表设计需经历严谨的规划与编码环节。第一步是数据分布规则的确定。以支付流水表为例,可采用哈希取模法:对供应商ID或支付单号进行一致性哈希计算,将结果对数据库实例数取模,从而决定数据存储的物理位置。这一方法能有效避免热点问题,但需权衡扩展性。另一种是基于时间范围拆分区,例如按月或按季度划分,这对应付系统中周期性结算场景尤为适用。接下来是数据迁移,这通常是重构中最具风险的部分。为保证系统不间断运行,常采用双写机制,即旧库与新库同时写入数据,并通过增量同步逐步完成历史数据的迁移。在此过程中,必须引入严格的校验逻辑,确保记录一致性与完整性。
在架构层,中间件的引入成为必然选择。许多团队会选用如ShardingSphere、MyCAT或Vitess等分库分表中间件。这些工具能自动将SQL请求路由至正确的分片。例如,当用户查询某供应商近三个月的应付余额时,中间件会识别查询条件,仅访问包含该供应商数据的零星片段,从而大幅提升查询效率。同时,全局主键的生成机制也需要重新设计。自增ID在分布式环境失效,转而采用雪花算法或分布式序列,确保唯一性与有序性。协同事务管理同样复杂,应付系统中涉及多方对账,跨库事务往往无法依靠单一数据库的ACID特性,需引入分布式事务框架如Seata,并采取TCC模式或SAGA模式来平衡一致性、可用性与性能。
实现分库分表绝非一帆风顺。挑战与代价贯穿于全生命周期。跨片查询的复杂性显著提升。应付系统中,经常涉及全局统计报表,如所有供应商的应付总额计费。在分库分表环境下,这类操作需遍历所有分片并汇总结果,不仅性能开销巨大,还可能因分片延迟导致数据不一致。这要求技术上引入聚合查询引擎或预计算机制,例如建立报表中间表,定期汇总数据。数据分布不均问题在实践中尤为棘手。哈希取模若未平衡,可能导致部分分片负载过高,而其他分片闲置。此时需要权衡扩容规划或引入一致性哈希与虚拟节点机制。再者,运维复杂度显着增加。多数据库实例的监控、备份、连接池管理以及网络延迟优化都成为日常负担,一旦某分片数据库故障,可能只影响部分用户,但故障恢复流程却因数据分散而变得更复杂。
应付系统对数据一致性要求极高,任何余额偏差都会影响财务结算。分库分表后,跨库操作无法保证强一致性,开发者不得不依赖最终一致性模型。设计中往往需要引入补偿机制,如对账系统定期自动比对支付记录与结算账单,发现差异立即触发回滚或重试。而对实时性要求严苛的支付扣款场景,则需借助缓存或本地状态优化延迟风险。历史数据的重构也是潜在挑战。旧系统庞大且杂乱的遗留数据可能缺乏分片钥匙,在分表转换中,若不慎按错误字段分布,将导致数据孤岛,最终影响业务运营。
经过这一系列分析可见,应付系统海量数据的分库分表重构是一个权衡性能、一致性与复杂度的大工程。它不仅改变了物理数据库结构,更深刻影响了代码设计、运维模式与业务逻辑。虽然挑战众多,但从长期视角看,成功实施分库分表能显著提升应付系统的吞吐能力,缩短支付处理链路,增强系统的弹性伸缩性。在未来数据量持续增长的趋势下,这一策略虽非唯一出路,但已是应付管理系统保持优质运转的重要基石。企业应在充分评估自身业务需求与团队技术底蕴后,审慎推进这一架构演进,方能在海量数据冲击下实现稳定与成长的双赢。
快手携手阿里云打造弹性架构,轻松应对百万级秒杀
快手携手阿里云打造的弹性架构,通过混合云模式与分布式系统设计,成功应对了百万级秒杀场景的极端流量挑战。以下是具体技术实现与核心优势的详细分析:
一、技术挑战背景
二、弹性架构的核心设计
图:分布式系统通过微服务拆分与负载均衡实现高并发处理
三、技术实现的关键点
图:混合云架构通过动态资源分配实现成本与性能平衡
四、应用效果与行业价值
总结
快手与阿里云的合作,通过混合云弹性架构、分布式系统优化与全链路压测,构建了高可用、高扩展的秒杀技术体系。
该方案不仅解决了自身业务痛点,也为直播电商行业提供了可复制的技术路径,标志着行业从“资源驱动”向“技术驱动”的升级。
SANSAN新鲜事|场站数字化避“坑”指南
场站数字化避“坑”指南
场站数字化通过数字技术实现全面感知、自动化控制、智能化管理和可视化展示,可提升效率、降低成本、保障安全、优化服务。但在实施过程中,需警惕以下关键环节的潜在风险,并采取针对性措施规避:
一、数据采集环节:传感器协议复杂导致系统架构臃肿
图1 三三开源物联网平台架构图
二、数据分析与处理环节:数据量激增导致性能瓶颈
三、AI分析环节:特征数据少、样本不足导致模型失效
图2 三三物联网平台AI视频分析应用
四、数字孪生环节:建模成本高、工期超支
图3 化工厂数字孪生体
五、定位技术环节:精度与成本失衡
图4 定位技术在场站中的应用
六、需求分析环节:项目规划缺失导致失败
七、实施流程环节:硬件/软件选型与开发风险
总结:借助成熟平台降低风险
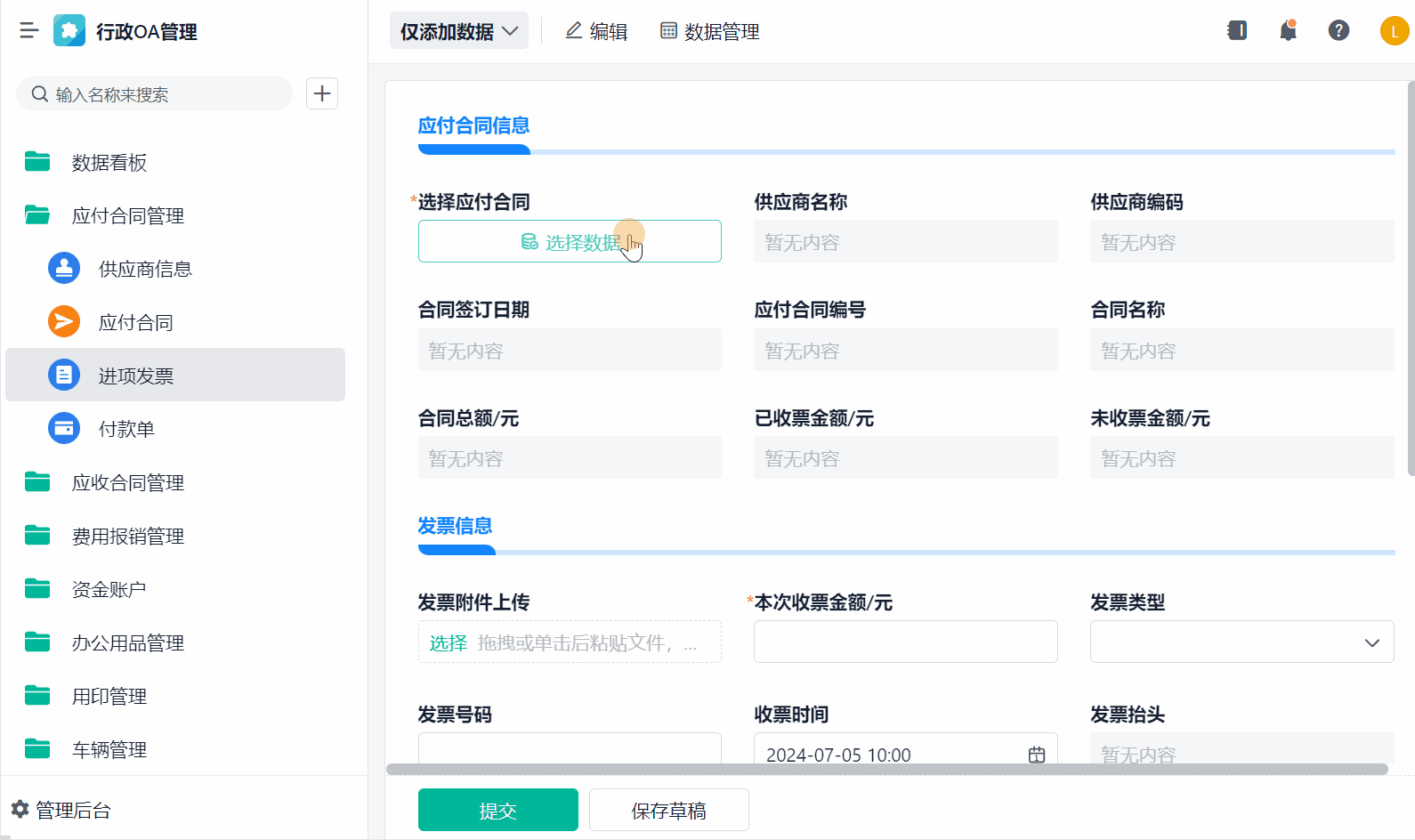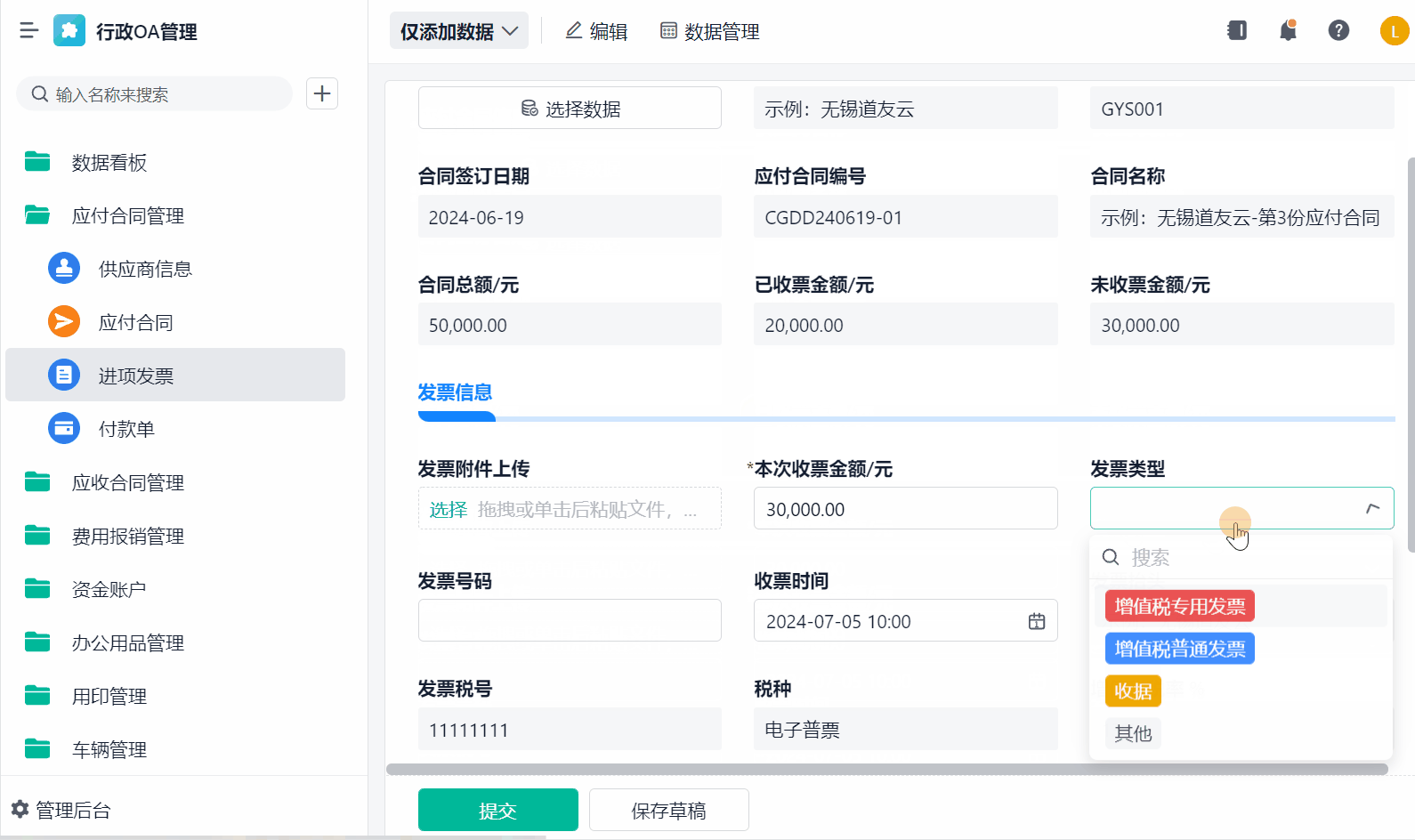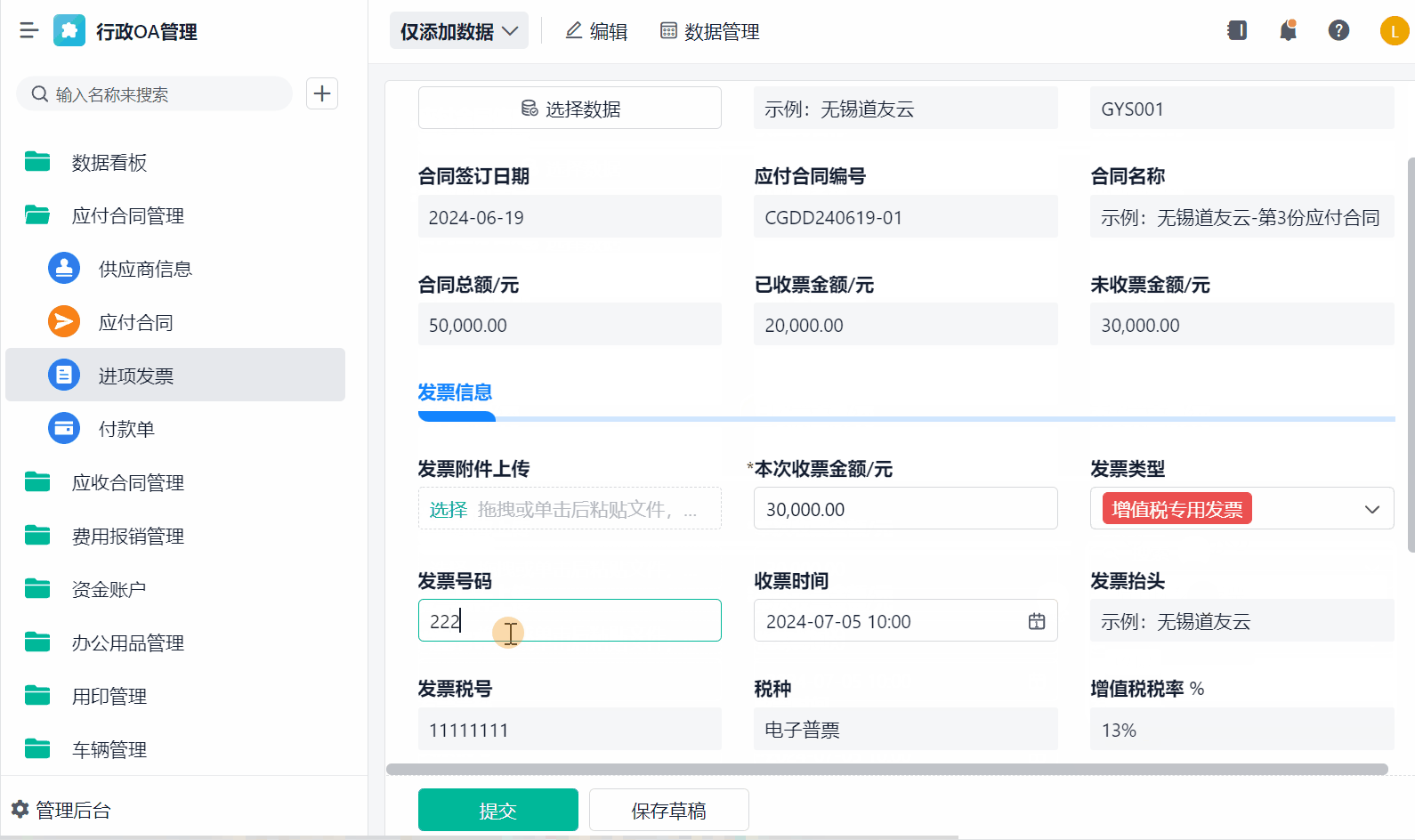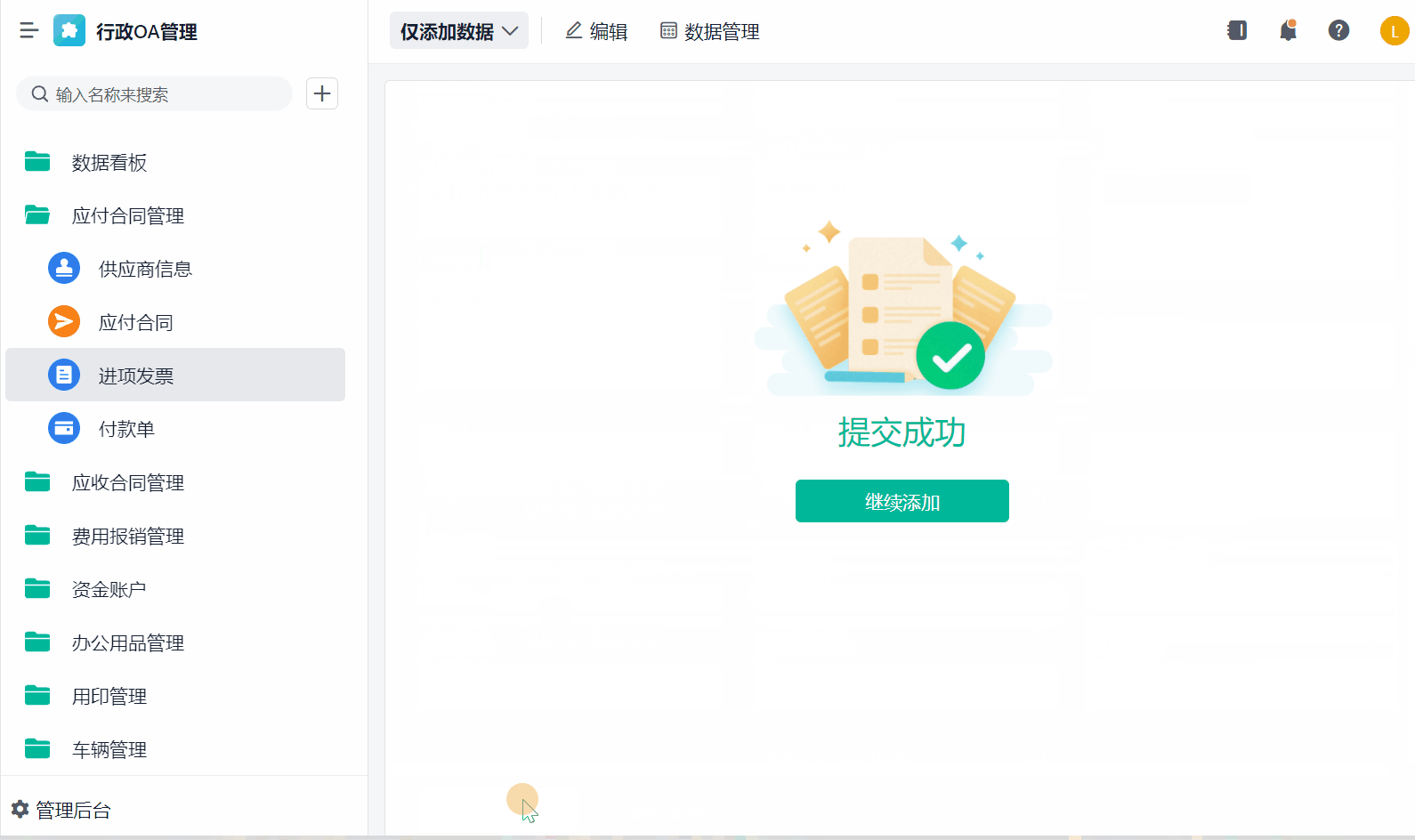
场站数字化需统筹技术、成本与需求,避免盲目追求“大而全”。
基于三三物联网平台的场站数字化方案,通过模块化架构、行业经验沉淀和最佳实践,可帮助企业规避多数常见风险,提升项目成功率。
三三物联网平台官网:技术交流QQ群
分而治之 — 浅谈分库分表及实践之路 | 京东云技术团队
分库分表是应对海量数据存储与查询性能下降的核心解决方案,其核心思想为“分而治之”,通过物理拆分数据降低单库单表压力,结合中间件或客户端模式实现分布式数据管理。
一、分库分表的必要性
二、数据库架构方案对比
三、分库分表技术选型1. 中间件模式
2. 客户端模式
对比结论:
四、Sharding-JDBC接入实战1. 组件集成<dependency><groupId></groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.0.0</version></dependency><dependency><groupId></groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>3.4.0</version></dependency>2. 数据源配置
3. Sharding-JDBC核心配置====ds-0,ds-1# 数据源配置-url=jdbc:mysql://host1:3306/-url=jdbc:mysql://host2:3306/db1# 分片策略-column=user_-algorithm-name=-tables[0]=t_order,t_order_-tables=t_address
五、实践建议
总结:分库分表是海量数据场景下的必经之路,需结合业务特点选择架构模式(中间件或客户端),并通过合理的分片策略和配置优化实现高性能与可扩展性。
Sharding-JDBC因其轻量级和兼容性成为Java生态的首选方案。













暂无评论内容